나만의 챗봇 AI를 갖고 싶다구요?

그렇다면 올라마(Ollama)를 권해 드립니다.
리눅스 서버를 권해드리는데요. vga 그래픽 카드가 있으면 좋겠지만 없어도 돌아갑니다. ( 좀 느리긴 하지만.. )
메모리는 16G 정도는 되어야 메모리 부족으로 서버가 뻗는 일이 없습니다.
약간의 리눅스 지식이 있는 분을 대상으로 한 내용입니다.
올라마 설치
저는 구글 GCP 의 CentOS 9 Stream 에 설치를 시도해 보았습니다.
CentOS 가 단종되고 Rocky Linux 로 대체되었다고 잘못 알고 계신분들이 많으나 CentOS 는 건제하며 GCP에서 O/S모델을 선택하여 설치가 가능합니다. 참고로 Rocky Linux 는 CentOS의 동생같은 존재입니다.
zstd 설치
Ollama 설치파일은 성능이 매우 좋은 지스탠다드(Z-standard) 압축 기술로 파일이 압축되었습니다.
그렇기에 zstd 패키지를 먼저 설치해야 합니다.
root 계정에서 실행합니다. ( sudo 매번 앞에 붙이기 귀차니즘으로.. )
dnf install -y zstd올라마 설치
이어서 올라마를 설치합니다.
curl -fsSL https://ollama.com/install.sh | sh그래픽 카드 설정
아래는 그래픽 카드가 있을 경우 설정하는 부분인데 그래픽 카드가 없는 서버라 테스트하지는 못했습니다.
설치 후 서버 재시작이 필요합니다.
# 1. EPEL 저장소 추가 (필수 의존성 패키지용)
dnf install -y epel-release
# 2. NVIDIA CUDA 저장소 추가 (RHEL 9용)
dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel9/x86_64/cuda-rhel9.repo
# 3. 드라이버 및 CUDA 툴킷 설치
dnf module install -y nvidia-driver:latest-dkms
dnf install -y cuda-toolkit올라마 구동
올라마를 서비스로 작동하도록 구동합니다,
systemctl start ollama
서버가 재시작될 때 자동 구동하기 위해 아래 명령도 추가로 실행해줍니다.
systemctl enable ollama아래 명령들은 각각 올라마 구동 정지, 상태 확인 명령입니다.
systemctl stop ollama
systemctl status ollama모델 다운로드 ( qwen 2.5 )
올라마는 LLM 을 실행하는 AI 엔진입니다, 그래서 단독으로 작동하지는 않는데요.
게임으로 치자면 올라마는 언리얼 엔진이나 유니티 엔진같은 플랫폼이지, 게임 컨텐츠가 아니기 때문입니다.
이 엔진이 작동하기 위해서는 ‘llama’ 나 ‘qwen’ 등의 AI모델이 필요한데요.
사용하는 AI 모델에 따라 실제 AI 품질이 결정됩니다.
한글 표현이 잘 되는 모델로는 qwen 2.5 모델을 추천합니다.
알리바바에서 만들었지만 무료 모델 중 한국어 표현 능력이 매우 뛰어 납니다.
다른 AI는 한글이 나오다 갑자기 이상한 외계어가 나오기도 하고 좀.. 그렇습니다.
그리고 코딩 능력도 괜찮다고 하네요.
qwen2.5에서도 7b와 3b가 추천되는데요.
7b가 더 지능이 높다고 보시면 됩니다. 하지만 그만큼 속도가 더 느립니다.
마음에 드는 걸로 다운로드 합니다. 2개 모두 다운로드해 사용할 때 선택할 수도 있습니다.
# 코딩 및 한국어 성능이 좋은 Qwen 2.5 (7B)
ollama pull qwen2.5:7b
# 3b 하위 모델 다운로드
ollama pull qwen2.5:3b다운받은 모델 조회 명령입니다.
ollama list어디 볼까? 테스트!
다운받은 올라마는 터미널 창에서 아래 명령으로 테스트할 수 있습니다.
따옴표 안에 문구를 원하는 문구로 바꿔 보세요.
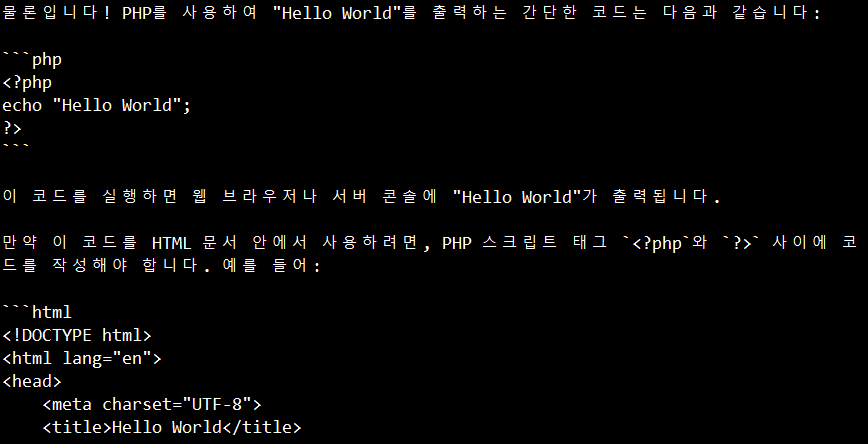
ollama run qwen2.5:7b "PHP로 Hello World 출력하는 코드 짜줘"아래와 같이 결과가 나온다면 성공!